
Open source compliance has become a pressing concern for every software team that ships code built on freely available libraries. When your project relies on dozens or even hundreds of open source dependencies, understanding the license obligations tied to each one is not optional. A single overlooked copyleft license can expose your organization to legal claims, forced code disclosure, or costly remediation.
AI code license audit tools now make it possible to scan entire codebases and flag risks automatically, but the technology only works if you follow a disciplined process.
This guide walks you through four practical steps to build a reliable AI-powered code audit workflow that catches license risks before they become legal problems. Whether you manage a startup's codebase or lead engineering at an enterprise, these steps apply equally. The stakes are real: litigation, injunctions, and reputational damage are all documented outcomes of open source non-compliance.
Key Takeaways
- Create a software bill of materials before writing any compliance policy.
- Automate license risk detection using AI-powered code audit tools in your CI pipeline.
- Classify licenses into permissive, weak copyleft, and strong copyleft categories for clear decisions.
- Train your developers on the top five license obligations they encounter daily.
- Review and update your open source compliance policy at least quarterly.
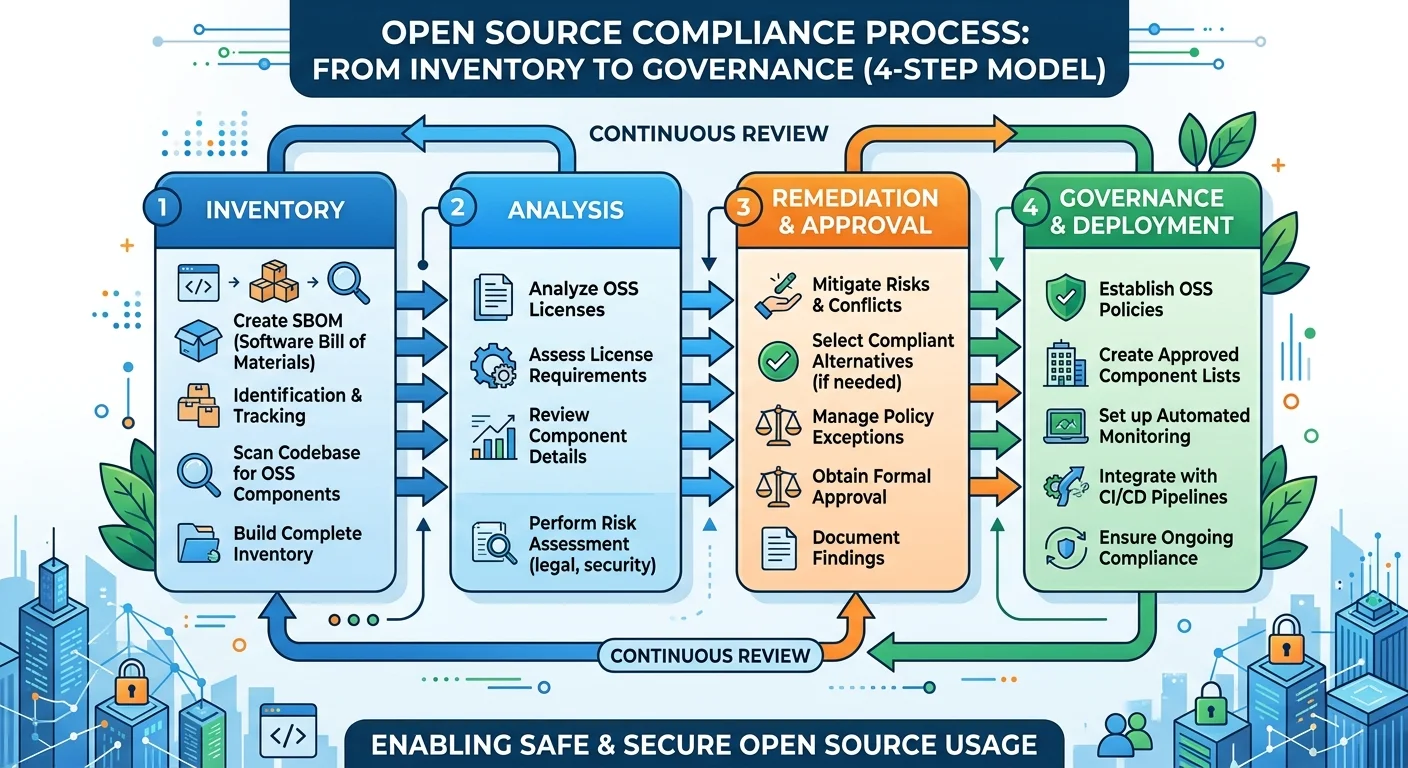
Step 1: Inventory Your Open Source Dependencies
Build Your SBOM
You cannot manage what you have not measured. The first action is generating a complete Software Bill of Materials (SBOM) that lists every open source component in your project, along with its version, origin, and declared license. Tools like Syft, CycloneDX, and SPDX generators produce machine-readable SBOMs in standard formats. Run these tools against every repository your team maintains, not just the primary application repo.
An SBOM is only useful if it stays current. Stale inventories miss newly added packages and version upgrades that may carry different license terms. Schedule SBOM generation as part of every build or, at minimum, every release cycle. Store the output in a centralized location where your legal and engineering teams can both access it. This shared visibility prevents the "nobody knew we used that library" scenario that leads to compliance failures.
Map Transitive Dependencies
Direct dependencies are only the surface layer. A typical Node.js project pulls in hundreds of transitive dependencies, each carrying its own license. Your SBOM tool should recursively resolve the full dependency tree. In practice, teams using npm, Maven, or pip often discover that over 80% of their open source components are transitive, meaning a developer never explicitly chose them. Ignoring these layers is the most common source of hidden license risk.
Read also: What Is EU AI Act Compliance? A Complete Guide
Pay special attention to dependencies that bundle other projects internally. Some packages vendor third-party code without declaring it in their package manifest. Manual spot checks of high-risk components supplement automated scans. If a library's repository includes a "vendor" or "third_party" directory, inspect its contents and record any additional licenses you find. This diligence prevents surprises during due diligence events like acquisitions or IPO preparations.
Use "npm ls --all" or "mvn dependency:tree" to visualize your full transitive dependency graph before running license scans.
Step 2: Classify Licenses and Assess Risk
License Categories That Matter
Not all open source licenses carry the same obligations. The practical approach is to group them into three categories: permissive (MIT, BSD, Apache 2.0), weak copyleft (LGPL, MPL), and strong copyleft (GPL, AGPL). Permissive licenses generally allow commercial use with minimal requirements, typically attribution. Copyleft licenses require you to distribute derivative works under the same terms, which can force disclosure of proprietary source code if you link or modify the component.
| License | Category | Commercial Use | Source Disclosure Required | Key Obligation |
|---|---|---|---|---|
| MIT | Permissive | Yes | No | Include copyright notice |
| Apache 2.0 | Permissive | Yes | No | State changes, include NOTICE |
| LGPL 2.1 | Weak Copyleft | Yes | Modified files only | Allow relinking |
| GPL 3.0 | Strong Copyleft | Conditional | Yes | Release full source of derivative |
| AGPL 3.0 | Strong Copyleft | Conditional | Yes (including SaaS) | Provide source to network users |
Risk Scoring in Practice
Assign a numeric risk score to each category so that automated tools can flag violations without human review of every package. For example, score permissive licenses at 1, weak copyleft at 5, strong copyleft at 9, and unknown or custom licenses at 10. Any component scoring above your threshold (say, 5 for a proprietary SaaS product) should trigger a manual review by your legal team before the code merges. This scoring model turns subjective license interpretation into a repeatable, auditable process.
AGPL-licensed components trigger source disclosure obligations even for server-side-only software. Do not assume SaaS deployment exempts you from copyleft requirements.
License compatibility is another dimension. Two individually acceptable licenses may conflict when combined in the same binary. The Apache 2.0 license, for instance, is compatible with GPL 3.0 in one direction but not the other. Track these interactions in a compatibility matrix that your license checker references during scans. Organizations like the Free Software Foundation and the Open Source Initiative publish guidance on compatibility, and your policy should reference these authoritative sources.
"A single AGPL dependency buried three layers deep in your dependency tree can legally obligate you to release your entire application's source code."
Step 3: Automate Compliance Checks with AI Tools
Choosing the Right License Checker
Manual compliance review does not scale beyond a handful of dependencies. Modern AI code audit tools analyze license text, detect code snippets copied from open source projects, and identify license conflicts across your dependency graph. Products like FOSSA, Snyk, Black Duck, and ScanCode use natural language processing to match license text against known templates, catching cases where a developer modified standard license wording. Some teams also explore open source LLMs for coding tasks that can assist in interpreting ambiguous license clauses.
When evaluating a license checker, prioritize accuracy over speed. False negatives (missed violations) are far more dangerous than false positives. Check whether the tool supports your package ecosystems: npm, PyPI, Maven, Go modules, and container images all present different scanning challenges. Also confirm that the tool can detect code-level copying, not just declared package licenses. Snippets copied from a GPL project into your codebase carry the same obligations as a full dependency.
Integrating Into Your Pipeline
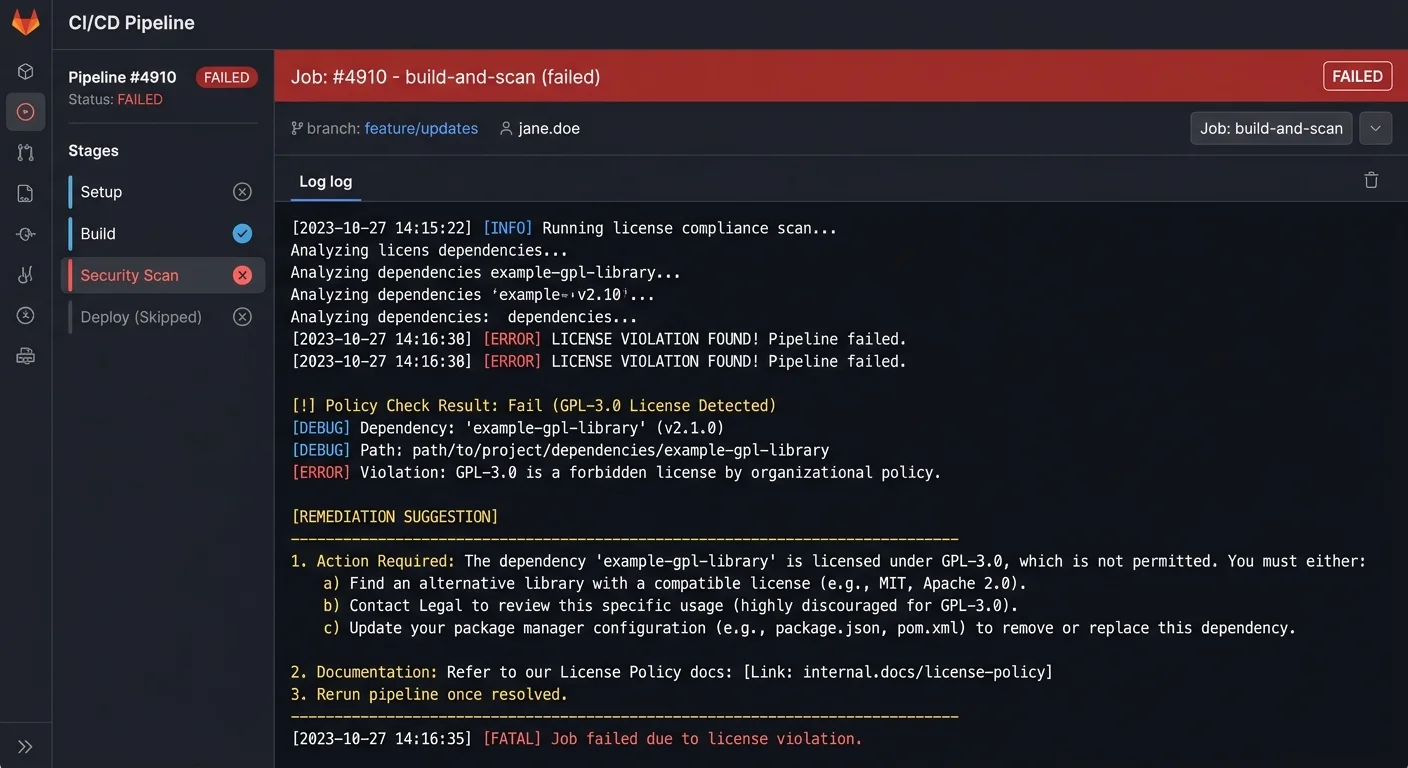
The most effective placement for a license checker is in your CI/CD pipeline as a build gate. Configure the tool to fail builds when it detects a license above your risk threshold or when it finds an unresolvable license conflict. This enforcement point catches issues before they reach production, when remediation costs are lowest. GitHub Actions, GitLab CI, and Jenkins all support integration with major scanning tools through plugins or CLI commands.
Do not stop at blocking bad licenses. Configure your tool to generate compliance reports for each release, including attribution notices, license texts, and SBOM exports. These artifacts serve as evidence of your compliance program if questions arise during a customer audit, acquisition, or legal dispute. Automate the generation and storage of these reports so that they are always available without manual effort from your engineering team.
Some license scanners produce different results depending on whether they analyze source archives or compiled binaries. Run scans on source code for the most accurate license detection.
Step 4: Establish Governance and Developer Training
Writing a Practical Policy
Tools without policy are just noise generators. Write a concise open source compliance policy that specifies which license categories are approved, which require legal review, and which are prohibited outright. Keep the document under three pages so developers actually read it. Include a decision tree or flowchart that a developer can follow when evaluating a new dependency. Assign an owner (often a senior engineer or engineering manager) who has authority to grant exceptions and escalate ambiguous cases.
Your policy should also address contribution back to open source projects. When your developers submit patches upstream, they may be agreeing to Contributor License Agreements that grant the upstream project certain rights over your code. Define clear guidelines for when contributions are acceptable and require sign-off from a manager or legal contact for contributions to projects governed by strong copyleft licenses. This outbound compliance often receives less attention than inbound dependency management, but it carries real IP risks.
Maintain a pre-approved dependency list that developers can pull from without waiting for legal review, speeding up development while maintaining compliance.
Training That Sticks
Annual compliance training slides do not change behavior. Instead, embed short, scenario-based training into your onboarding process and quarterly engineering meetings. Present real cases: the Cisco lawsuit over GPL violations, the Artifex v. Hancom case involving dual-licensed PDF libraries, or Google's years-long Oracle v. Google API copyright battle. These concrete examples make abstract license concepts tangible. Developers remember stories better than bullet points on a slide deck.
Supplement formal training with in-workflow guidance. When your license checker flags a component, include a brief explanation of why in the build output, not just a failure message. Link to your internal policy document. Consider creating a Slack channel or mailing list where developers can ask license questions and get quick answers from the designated compliance owner. The goal is reducing friction so that developers treat compliance as part of their normal workflow rather than an obstacle imposed by legal.
Frequently Asked Questions
?How do I keep my SBOM current as dependencies change?
?Is scanning direct dependencies enough, or do I need transitive ones too?
?How long does setting up an AI license audit CI pipeline actually take?
?Can a vendored third-party library inside a package slip past automated scans?
Final Thoughts
Open source compliance is a continuous discipline, not a one-time checkbox exercise. The four steps outlined here, from building your SBOM to training your developers, form a practical framework that scales with your codebase.
AI-powered license risk detection tools handle the heavy lifting, but they require accurate policies and informed engineers to be effective. Start with your inventory this week, automate your scans this month, and refine your governance every quarter. Your future self (and your legal team) will thank you.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.


